What is a Threat Library?
POSTED BY NEAL HUMPHREYFind out more about ThreatQ's Threat Library
The first thought that comes to mind is that these are two terms really don’t belong together. A dangerous library? Why would I go there?
The second thought that comes to mind is maybe we mean a malware farm. In a previous employer’s data center, there was a rack with the below picture taped to its front. For those who aren’t familiar, this is an image of the Real Ghostbusters’ Ecto-containment unit. You did not connect to anything in that rack, ever.

Source: Ecto-containment unit, Ghostbuster’s (1986 TV Series)
My definition of the term “threat library” overlaps with this somewhat. It is a collection area for malware samples, and for other nasty things that could hurt systems. But it’s also a lot more than that.
The third thought is that at this point, I have used the term ‘threat’ just once, which feels wrong. See, where I sit I hear this term all the time. Whether it is from intelligence feeds or providers, from detection/prevention tool providers, from the Internet, from TV, the phrase seems to come from everywhere and everyone. The term ‘threat’ is overused and its definition is becoming extremely muddy as a result.
The fourth thought is that addressing all of these thoughts could get a bit lengthy. This is probably going to be a multi-part blog.
So, let’s get going and cover the first thought: “A dangerous library?”

Source: Ghostbusters (Movie, 1984)
When I think of a library, several visuals come to mind and the one above isn’t among them. Instead, this is what I envision:

Chetham’s Library, Manchester, UK
A library should be like the picture above: an uncluttered, well-organized storage location where people go not only to find specific information, but also to find related information. You shouldn’t expect to get in and out of a library in a few minutes..people find information, conduct research and actually do work within the walls of a library.
So, the first thing that a threat library needs to be able to do is to organize information. And not just organize it, but organize it in a way that makes sense to a threat team. If I expect things to be organized in alphabetical order and they are organized by time of entry, well… I am going to have a problem finding what I need.
The second thing a library needs to be is accessible. Having organized information isn’t useful if it isn’t available. People must be able to get to it easily and quickly.
The third thing a library needs is to keep records of the information that is available. If the piece of information I am looking for isn’t there, I need to know whether it has ever there, or if it has simply been checked out. If it has been checked out, the library should know who checked it out, when, where, and when it is expected to be returned.
Now let’s take these three things and put them into more specific wording as it relates to threats and security.
A threat library should:
- Serve as an organized, indexed and searchable location for structured and un-structured security information.
- Be easily accessible not only from a native interface, web or otherwise, but it should also provide access to the data from remote systems through an API or other easily accessible means.
- Automatically aggregate and normalize data while maintaining a consistent trail of information on what has been added or modified, by whom, and when.
Let’s break down each of these points.
A threat library should serve as an organized, indexed and searchable location for structured and un-unstructured security information.
Analysts are packrats. We all know it, some admit it. That one little scrap of information could be valuable later on; it might relate to a bigger thing and provide a level of meaning beyond what we currently understand through it. It’s the way that things go. You would use a threat library to help you store that little nugget, and apply some context to it so that it is discoverable later on, and easier to relate data points to. The alternative — desks full of spreadsheets and PDF briefs, Sharepoint locations, Google drives, emails, text messages, etc. — can look like this after a long week:

Yes, that is one of my workbenches after a weekend project, or two, or three. Trust me, you don’t want this.
A library should automatically pull information in for you, to the best of its capability, and automatically organize it in a way that makes sense to your organization. A library truly is nothing more than a database, so what is different about a Threat Library from a standard library? And why does ThreatQ talk so much about a threat library?
Let’s start with the difference between a library and a threat library. In general, a database, or library, is going to collect the information it is given in the way it is told to. A threat library is different as the type of information that is added to it can constantly change. Let’s take my workbench (sorry) from the image above as an example. I have a spot for screws, I have a spot for nails, I have a spot for screwdrivers, I have a spot for saw blades, etc. Those can be considered structured data. I know what to expect and where to put it.
A threat library has to take new additions into account and allow you to move items or relationships around. If I added duct tape to the workbench, or painter’s tape, or carpenter pencils, where do those go? How should those be treated?
In the threat intelligence market this equates to structured and unstructured intelligence. Structured intel is the pieces of information we expect to get, the feeds and providers, the atomic indicators I get every morning on who was doing bad things on the Internet the day before. All threat intelligence platforms are capable of accepting this information. The differentiation is based on the kind of control you have over the data before it is entered or after it has been automatically organized. Can you tag it differently? Can you change a mapping? Can you build that out as a new relationship to some other previously unrelated piece of information? Structured information isn’t always indicators. It can also be CVEs or other vulnerability information, TTPs, adversary briefs, signatures or rules, email messages, or malware samples. All types of data from potentially dissimilar locations over structured routes all being saved and related together can be considered structured information.
Unstructured information may be even more important. It takes time and resources for people to find, collect and organize information before publishing that data as intelligence. Analysts today spend a good bit of time browsing the web for data, or what could seemingly be bread crumbs. A library needs to give analysts a place to store those unrefined ideas and pieces of information, and needs to do so in a flexible manner. Being forced to abide by a particular process or method to categorize this unstructured data limits its viability. The workflow and location from where data is gathered guides the process, so, above all, the library must be flexible and allow anything to be linked to anything else in the system.
Unstructured PDF example:
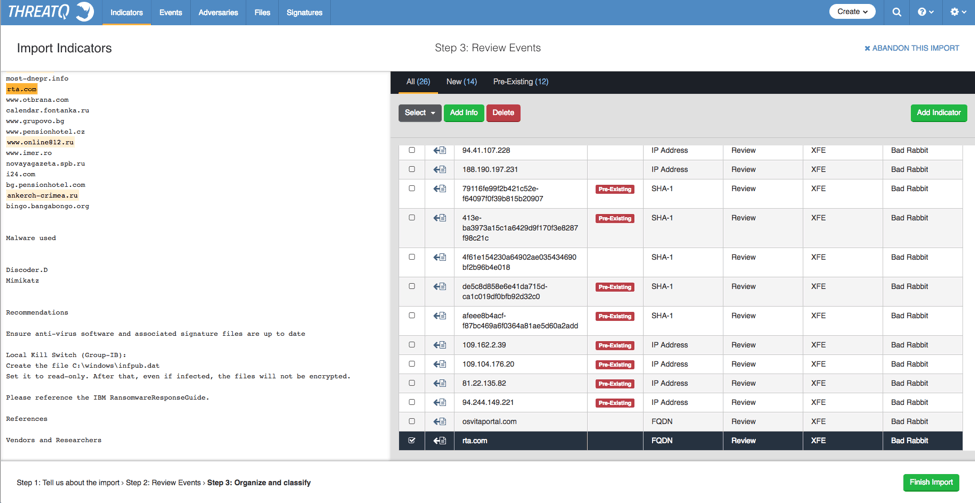
Figure 1: Indicator Import from ThreatQ version 3.4.3
In the image above, we have a STIX collection that has been parsed automatically by the ThreatQ threat intelligence platform. It’s ready to be added to the threat library. Earlier, I had the opportunity to add context based on what I knew about the file I was uploading: source, name and unique tags or values I want to apply to the document.
In this image, I have a left-hand section that is the unstructured text of the document parsed. On the right-hand section I have the structured indicators that have been parsed from the document, and the ability to look for these indicators within the unstructured text on the left. Why is this important? First of all, and this is landmark… wait for it..
Parsing makes mistakes. It misses things.
Okay, now you can take your jaw up off the floor after hearing a vendor admit that technology makes mistakes. You need to be able to validate the parser to gain confidence in what it finds, or more importantly in what it misses. You need to be able to read above and below the indicator so that you can add additional context or relationships to a single indicator or several indicators at a time.
Context is always the killer. The data that is collected into the threat library needs to have personalized context for the company or network it is being used to protect. It needs to be relevant reference information.
Let’s move on to the next aspect of the definition of a threat library.
A threat library should be easily accessible not only from a native interface, web or otherwise, but it should also provide native access to the data from remote systems through an API or other easily accessible means.
A library you can’t get to might as well not be there. A library you can’t read a book in might as well not exist either. So, users need access to the data and they need to be able to read the data.

Doors..maybe?
When describing access, the industry often refers to a single pane of glass. But what does this mean?

Had to. It’s Sam Jackson!
Companies are divided into many different groups. They have to be in order to work effectively. Each has a different focus and a different set of skills. We need the different groups to be able to communicate effectively, but we don’t need yet another interface that we expect each team to log into and have a magical experience in because that just isn’t going to happen.
What should happen is that the library should be available through a security conduit that pipes the context and information another team may need directly into the tool they are using. In effect, they can view what they need through a single pane of glass. There should be no need to go to the library to ask for that book; the book should be presented when the user asks for that additional information.
Here is a simple screenshot from a ThreatQ-integrated Resilient Server. Why is this important? Well the Incident Response (IR) team member working on this case isn’t going back and forth to the ThreatQ threat library. They can but, why should they? The context from the threat library is already on their screen as shown below.
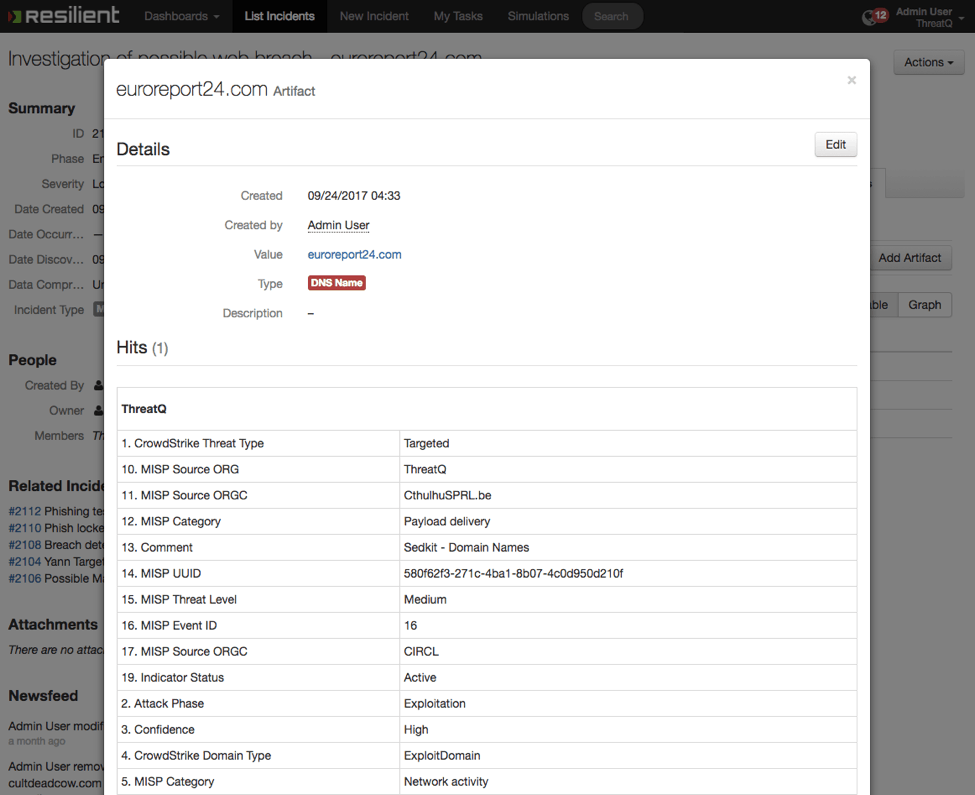
Figure 2: Resilient Artifact detail with embedded ThreatQ context.
Not only can they view the data natively, they can also interact with the data. Need more related information? Just click “Get related information from ThreatQ.” Think that a co-worker made a mistake in declaring this artifact to be malicious? Mark it as a false positive and the indicator is modified in the threat library immediately.
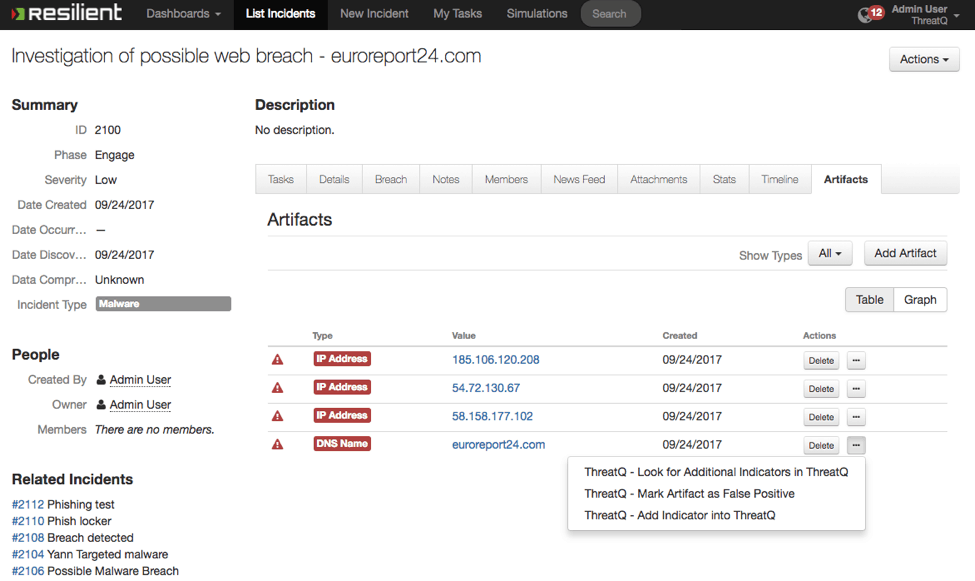
Figure 3: Resilient GUI Actions that affect library information in the ThreatQ threat intelligence platform.
That action could have trickle-down effects throughout the rest of the connected infrastructure.
And now let’s consider the final aspect of a threat library.
It should automatically aggregate and normalize data while maintaining a consistent trail of information on what has been added or modified, by whom, and when.
Let’s follow through with the example above, because people make mistakes. The IR team decided that the artifact they were looking at is a false positive in a particular case. They marked it false positive and now you, as the Analyst, get the opportunity to verify their decision.
Was it just a false positive at that point in time?
Is it a consistent false positive for your company and should therefore be aged out? Should it be used just for reference from this point forward until new related information shows up?
This is up to you to decide. All the library can do is point you to the history section to help you understand the past.
The history section of any library is of critical importance. As the adage goes, “Those who forget history are doomed to repeat it.” But seriously, it really is important. Having an evidence trail to answer the following questions helps ensure the right feeds are on, the right enrichment is happening, the right scoring policy is in place, the works.
- What source initially created the indicator?
- Who added what attributes and their values and when?
- Who modified the score of the indicator manually?
- What other related information has come in on this indicator, and when?
- Was this indicator forwarded to the SIEM?
Do we have a SIEM sighting on this indicator before it was seen as part of the ticket? What ticket(s) was it part of in Resilient?
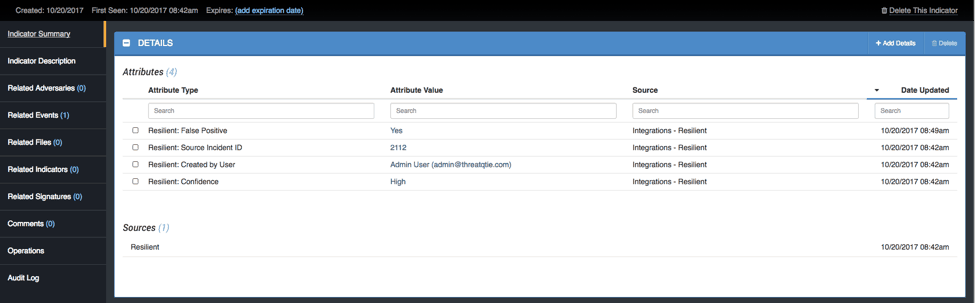
Figure 4: Indicators specific context organized in the ThreatQ Library
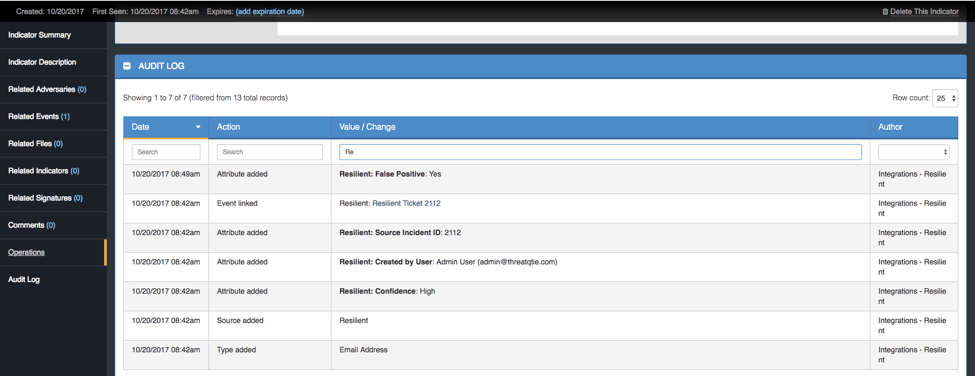
Figure 5: Indicator Audit log in the ThreatQ Library
Being able to get the answers to these questions quickly from the threat library allows decision makers to not only make informed decisions quickly, but also to understand the process and the past decisions that were made. From there you can make further refinements.
Does that process need to be updated or changed?
Do I need to look at my feeds or my scoring process?
The library has the history of all indicators, events, etc. It probably has answers to those questions too.
To summarize, a threat library is the heart of any threat intelligence platform. Without a customized threat library that allows users to handle integrations from any source, structured or unstructured, and allows them to validate the parsing how can you be sure you aren’t missing valuable context, or that the context is being catalogued but only a few people in the company can use or understand that context?
Used appropriately, a customized threat library becomes your company’s single source of truth for your security questions, including: Why was this blocked? What do we do about this malware family? Is that an indicator of drive-by traffic or something more targeted and what do we do next? This defines a security-driven threat library and is something not only your threat intel, or IR teams can use, but your security architecture can leverage as a force multiplier.
Coming soon: Structured and Un-Structured intelligence

0 Comments
Trackbacks/Pingbacks