Power the SOC of the Future with the DataLinq Engine – Part 2
LEON WARDIn my first blog in this series, we discussed the importance of data to the modern SOC, and the unique approach of ThreatQ DataLinq Engine to connect the dots across all data sources, tools and teams to accelerate detection, investigation and response. We developed the DataLinq Engine with the specific goal of optimizing the process of making sense out of data in order to reduce the unnecessary volume and resulting burden.
How the DataLinq Engine works
To take a strategic approach to using data, we must first deconstruct it, and then merge it into a collective many-to-many relational model that has multiple dimensions. The engine must focus on the goal of adding more value to existing data stores and systems that exist within the operational environment rather than merely duplicating or replacing them.
The DataLinq Engine follows a specific processing pipeline leading to a dynamic end-state that is constantly updating, evolving and learning. This method of processing is vastly different from a SIEM, Log manager, or legacy Threat Intelligence Platforms and follows five key stages: Ingest, Normalize, Correlate, Prioritize and Translate.
Here, we’re going to take a closer look at the first two stages, Ingest and Normalize.
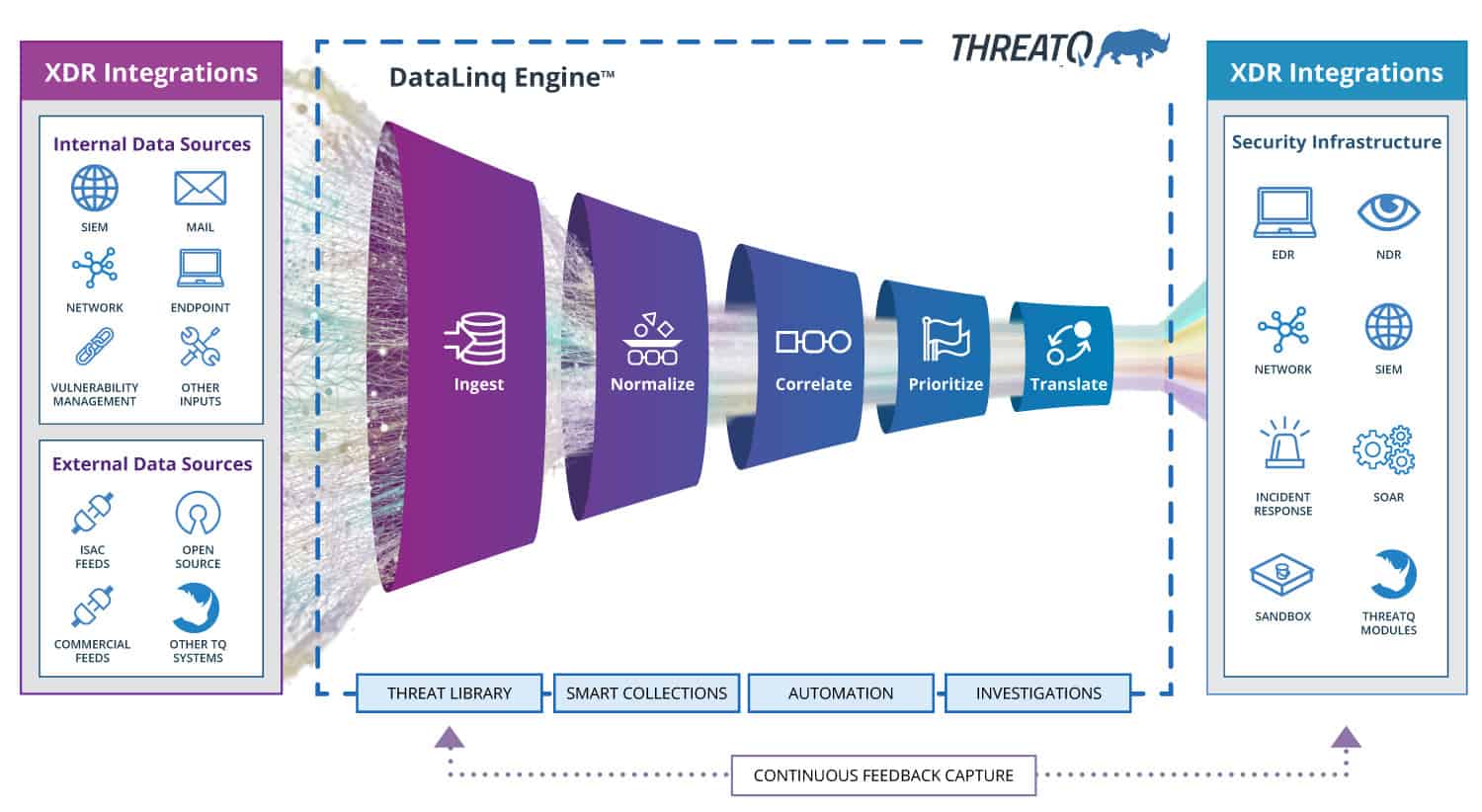
Ingest
The first stage in processing data is to gain access to input data. The DataLinq Engine supports a wide variety of sources including both internal and external; structured and unstructured; and standard or custom (see examples at https://marketplace.threatq.com).
Parsers can be applied for industry recognized formats such as email (EML), PDFs, YARA, OpenIOC, Snort/Suricata, XML, JSON, and plain text. The goal of the ingest stage is to identify key elements within a data object that can be useful for understanding it.
Consider a hypothetical single security data record that includes some form of observation or metadata in describing a threat or incident. It may be represented as a simple JSON object:
{
“observation_time”: 1634208760,
“event_id”: 1234,
“malware_family”: “emotet”,
“md5”: d8e8fca2dc0f896fd7cb4cb0031ba249,
“connection”: {
“from”: “source.example.com“,
“to”: “destination.example.com“
},
“URL”: “http://example.com:80/some/call/back?id=1”,
“detection type”: “C2”,
“source_identity”: {
“first_name”: “Joe”,
“last_name”: “smith”
},
“first_256_bytes_of_flow”: “xxxxxxxxxxx<omitted>”,
“pe_header”: {
<omitted>
}
}
There is much that we could pull from this sample record that is useful for analysis, detection, investigation and response activities. However, for the scope of this paper, we’ll summarize the elements within a data object into three different categories:
- Threat Objects: Elements that can help to identify key objects to statefully track, and to enable pivots across tools: Examples: Malware family names, identity data, file hash, urls, IP addresses.
- Object Context: Data that can enable the threat objects to be better understood. Examples: The Malware family name, the fact that c2 communications has been observed (and to where), identity information showing who has been impacted by it.
- Event Observation Metadata: This is information about the occurrence of a sighting or event raised, including elements that are specific to the use case of the reporting product or system. Examples: Detailed information about file contents, network flow or event identifiers. Generally, details are related to one specific observation.
If the goal is a dataset that can enable better coordination across existing systems and help users to take actions that span across systems, then we should focus on the first two categories, since doing so will enable simplified pivoting between tools, systems and datasets via a common denominator, but with added security context. To achieve this goal, we must also normalize the data.
The third category of data, event observation metadata, always has value and it is common to need some of it, but this is classically where existing data stores (e.g., Log repositories and SIEMs) have focused. So, it’s best to only take tactical elements to avoid falling into the “proliferation of datastores” trap.
Normalize
Normalization of data is a complex subject, but the scope of our needs allows us to simplify the goal. We need confidence that it is possible to identify functionally identical objects across different data sources when they are described in slightly different ways. For object values, the following must be considered with data normalization:
- Character encodings
- Whitespace
- Text case, in the context of the data being reported
- De-fang/re-fang processes (e.g., hxxp://example[.]com)
- Protocol specific elements, such as port number handling in urls (http://example.com:80 vs. http://example.com)
Normalization requirements extend beyond the object values to all the object context that is provided with them. The DataLinq Engine uses a configuration-driven approach to control how this context is normalized. Here are two small example snippets showing how timestamps are automatically normalized, and normalized mappings can be applied.
filters:
– parse-json
– get: results
– iterate
– filter-mapping:
created: timestamp
modified: timestamp
Figure 1. Configuration-controlled parsing of an array of JSON objects, with timestamp parsing applied to created and modified keys
– name: Target Industry.
value: !expr value.industries or [ ]
published_at: !expr value.created
Figure 2. Iterating over an array of context in an industries key
The DataLinq Engine breaks apart these complex data structures related to events, incidents and threat intelligence into atomic elements, so it can rebuild them with an aggregated view of the data from across all the sources, tools, services and users. This is critical to allow the correlation into a unified object to occur between different reporting sources, and also to relate other unified objects.
In my final blog in this series, we’ll take an in-depth look at the last three stages in the DataLinq Engine processing pipeline: Correlate, Prioritize and Translate.
Want to jump ahead? Download your copy of Accelerate Threat Detection & Response with DataLinq Engine.

0 Comments