Clustering IOCs
POSTED BY NIR YOSHAThere is something so absolutely freeing about staring at the stars. The milky way can be seen without a telescope. However, most stars are not visible to the naked eye. Star clusters can be discovered by their gravitational influence. For example, the center of a cluster could be detected when stars are circling around as if they were orbiting a really dense mass.
Figure 1: Star clusters
Honestly, Indicators of compromise (IOCs), are not as enjoyable to stare at as stars. However, similar stars, the cyber threat intelligence (CTI) landscape offers millions of IOCs that may or may not impact each other. While grouping IOCs can be seen as a pointless task at first glance, clustering IOCs can automate grouping and reveal valuable insights to the CTI, Security Operations Center (SOC) and Incident Response (IR) teams.
Clustering IOCs was the subject of my research and the topic of this article.
Why should I care?
IOCs, especially when coming from OSINT (Open-source Intelligence), are very noisy and unmanageable without some pre-processing. In addition to false positives, IOCs are often missing context, which makes them difficult to act on. Finally, priority of CTI risk is highly depending on likelihood and relevance of the IOCs to our organization and environment.
Background research
For my research, I used OSINT feeds, malware analysis reports and threat intelligence research papers. To better understand the IOCs meaning and correlation to an intrusion set, I have looked at the most common tactics, techniques and procedures (TTPs) used by adversaries and within cyber campaigns.
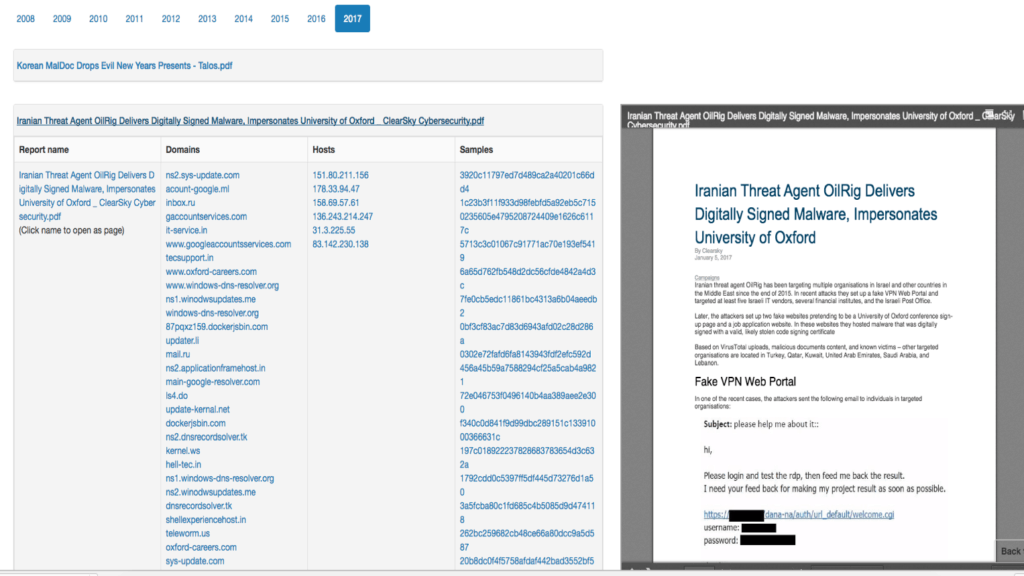
Figure 2: Source – threatminer.org
Figure 2 is an example of CTI report and its extracted IOCs. The main IOC types are malicious hosts (IPv4), Domains and malware samples (MD5 hash). The ThreatQ platform helped with enrichment in order to get more options for feature selection.
Malicious Host (IPv4)- geolocation (country, region, city), service provider, domain, ASN
Domains – top-level-domain, length, owner, application (eg. php, java etc.), target
Malware samples – malware type, hash value, file size, file name, target
Note – I have used statistical techniques when dealing with missing data, since dropping samples can bias the results of the analysis.
Links and IOCs groups
The true power of IOCs is realized when they are used in conjunction with each other to better enable contextual understanding for threat analysis. For the clustering algorithm, I have defined a cluster object based on the links between the IOCs.
Assembly (definition): Assembly is a group of IOCs and their extracted features that relate to each other either by association or composition. For example, a link between IOCs to a specific APT (advanced persistent threat) will be defined an assembly by association, where a link between IPs to their domain lookup will be defined assembly by composition. Assembly can include both association and composition relationship.
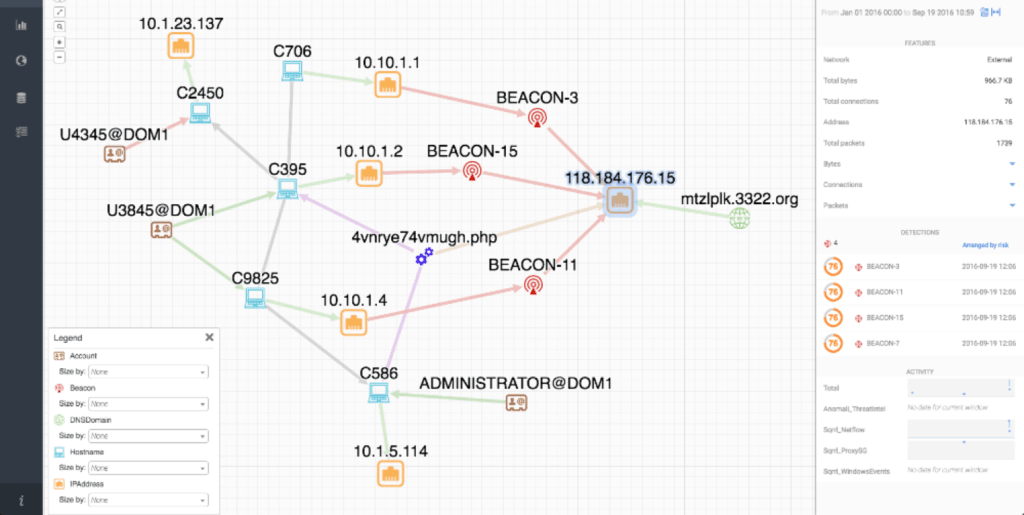
Figure 3: Assembly example Source: sqrrl.com
Figure 3 is an assembly that can be illustrated in a node graph where the IOCs are the nodes and the relationship types are the edges.
Distance between IOCs
The appropriate distance function between assemblies depends on the individual data set and intended use of the results.
IPv4 distance – distance between IPv4 geolocation (latitude and longitude) doesn’t work well, due to countries gap in size and scale. A better distance measure should consider IP subnets. For example 192[dot]168.3.5 is closer to 192[dot]168.7.9 than to 192[dot]166.3.5 based on the mutual prefix (from left) between the IPs.

Figure 4: 3-D scatter plot, Source: ThreatQuotient
Figure 4 is a 3-D scatter plot where axis X,Y show octets 3,4 value and Z shows octet 1 and 2 combined. Octet 3 and 4 do not contribute to IPv4 clusters.
Domains distance – for my research, I looked at two types of malicious domains: Domain Gnerator Algorithm (DGA) and misspelled domains. DGA distance from other domains could be defined by their character’s length. DGA domains are distinctively longer than other domains. For other domains, such as misspelled domains, a distance between strings can be used. There are few ways to measure distance between strings. In my research, I used the Levenshtein distance. Levenshtein distance is measured by the number of character deletions, insertions, or substitutions required to transform domain string A into domain string B.
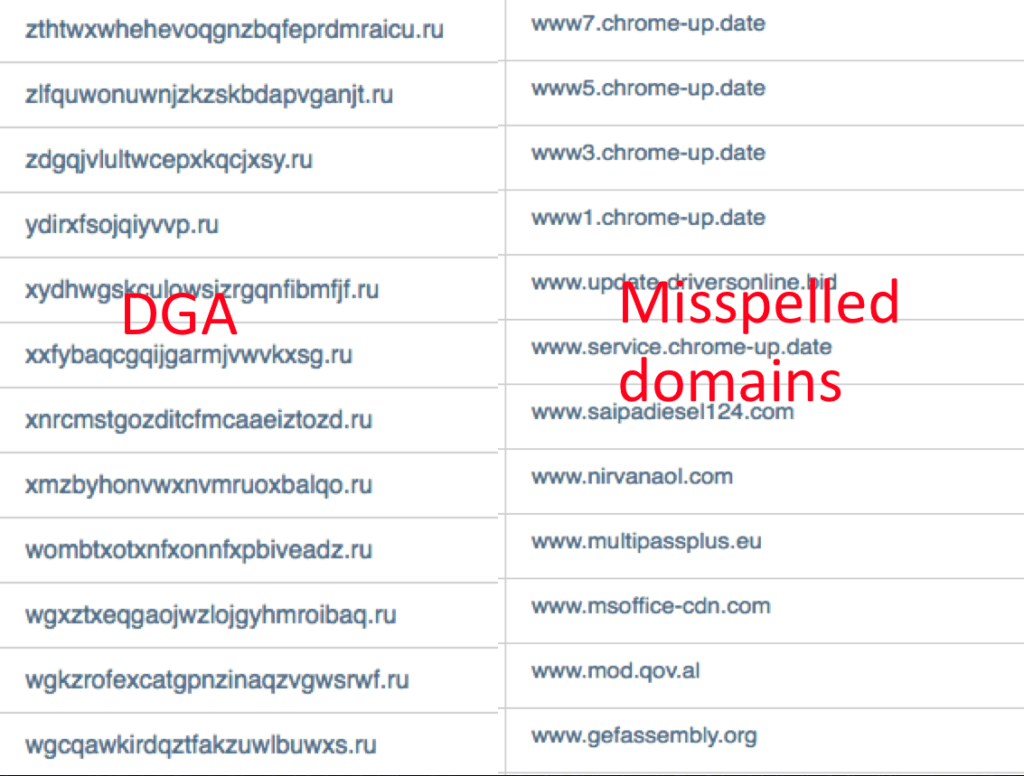
Figure 5: DGA Domains, Source: ThreatQuotient
In figure 5, the DGA domains length is higher than other domains in average. Other domains are likely related based on Levenshtein distance. In addition, top-level-domain (TLD) can be used as a classifier (.org, .biz, .ru etc.).
Conclusion
Unlike any other domain, threat intelligence datasets are a fast moving target. Dataset poisoning, evading techniques, obfuscating, jumping IPs and DGA are just few examples of what any machine learning model should deal with.
Nevertheless, working on datasets that focus on well defined periods of time and business requirements can result with valuable insights:
- Clusters by risks – based on likelihood and relevance score, clusters will likely help with priorities.
- Course of actions – based on similar attack vectors and related malware families, clusters will likely require similar mitigations.
- Attribution – based on similar source based characteristics and motivation, clusters will likely help with attribution.
Machine learning for CTI is only in its inception. CTI datasets keep on growing exponentially. Clustering and other machine learning domains will keep on playing a role in understanding threats in order to better protect our organizations.
Keep your eyes on the stars, and your feet on the ground.

0 Comments